什么是数据倾斜
最直白的语句来看数据倾斜就是数据里某一个key的值太多了,导致task处理其的时间远远超过其他任务,hadoop的常见现象就是任务卡在99%,迟迟不结束。我觉得可以理解为木桶原理,因为运行最慢的task拖慢了整个任务的运行时间。
不过也可以这么解释:数据倾斜就是我们在计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢。
一般表现为某个任务Reduce阶段卡在99%不动,以及随之而来的种种诡异现象。
数据倾斜的问题并不是随着节点的增多而解决的,比如看个例子:
- 公司 A : 1000万用户,10台64G服务器
- 公司 B : 10亿用户,1000台64G服务器
两个公司都部署了Hadoop集群。假设现在遇到了数据倾斜,发生什么?
公司A的数据童鞋在做join的时候发生了数据倾斜,会导致有几百万用户的相关数据集中到了一台服务器上,几百万的用户数据,感觉64G还是轻松的。
公司B的数据童鞋在做join的时候也发生了数据倾斜,可能会有1个亿的用户相关数据集中到了一台机器上了,一台机器估计就很难搞了,整个task会因为这个而卡住。
数据倾斜的原理
数据倾斜产生的原因
我们在做数据运算的时候,肯定会使用到count,distinct,group by,join/等操作,这些都会触发Shuffle操作,一但出现Shuffle过程中天量相同Key值的数据拉到一个或者少数几个节点上,就容易踩坑。。。
Shuffle
Shuffle过程在Hadoop或者Spark中都是至关重要的,产生的原因也很清晰明了,如下图所示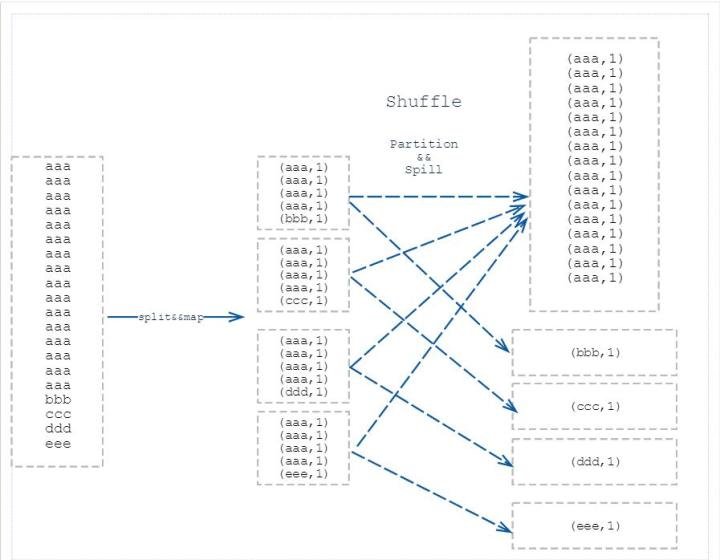
比如说
- 两个开发同学分别设计了user(userid,ip)表和ip_log(ip,logtime)表,其中user.ip的值如果获取不到的话,则默认为null,对于获取不到ip的用户,则取ip_log.ip=0,在这样的情况下,当两个表做join操作的时候,就很有可能卡住(空值由一个reduce处理)
- 业务上搞了大事,单个城市订单猛涨1000倍之类的。
常见情况参见:
| 关键词 | 情形 | 后果 |
|---|---|---|
| join | 其中一个表较小,但是key集中 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| join | 大表与大表,但是分桶的判断字段0值或空值过多 | 一个reduce处理,极其慢 |
| group by | group by维度过小,导致某值的数量过多 | 某reduce耗时久 |
| count distinct | 某特殊值过多 | 某reduce耗时久 |
数据倾斜解决
SQL调优
- join数据量太大的时候,可以考虑先distinct去重
- 大表Join大表,把空值的key变成一个字符串加上随机数,把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。(先对key做一层hash,先将数据打散让它的并行度变大,再汇集)
- join 操作中,使用 map join 在 map 端就先进行 join ,免得到reduce 时卡住
- 能先进行 group 操作的时候先进行 group 操作,把 key 先进行一次 reduce,之后再进行 count 或者 distinct count 操作。
- 特殊情况特殊处理,在业务逻辑优化效果的不大情况下,有些时候是可以将倾斜的数据单独拿出来处理。最后union回去。
参数调优
- set hive.map.aggr=true:在map中会做部分聚集操作,效率更高但需要更多的内存
- hive.groupby.skewindata=true:数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
- hive.auto.convert.join=true:自动开启mapjoin优化
- 未完待续