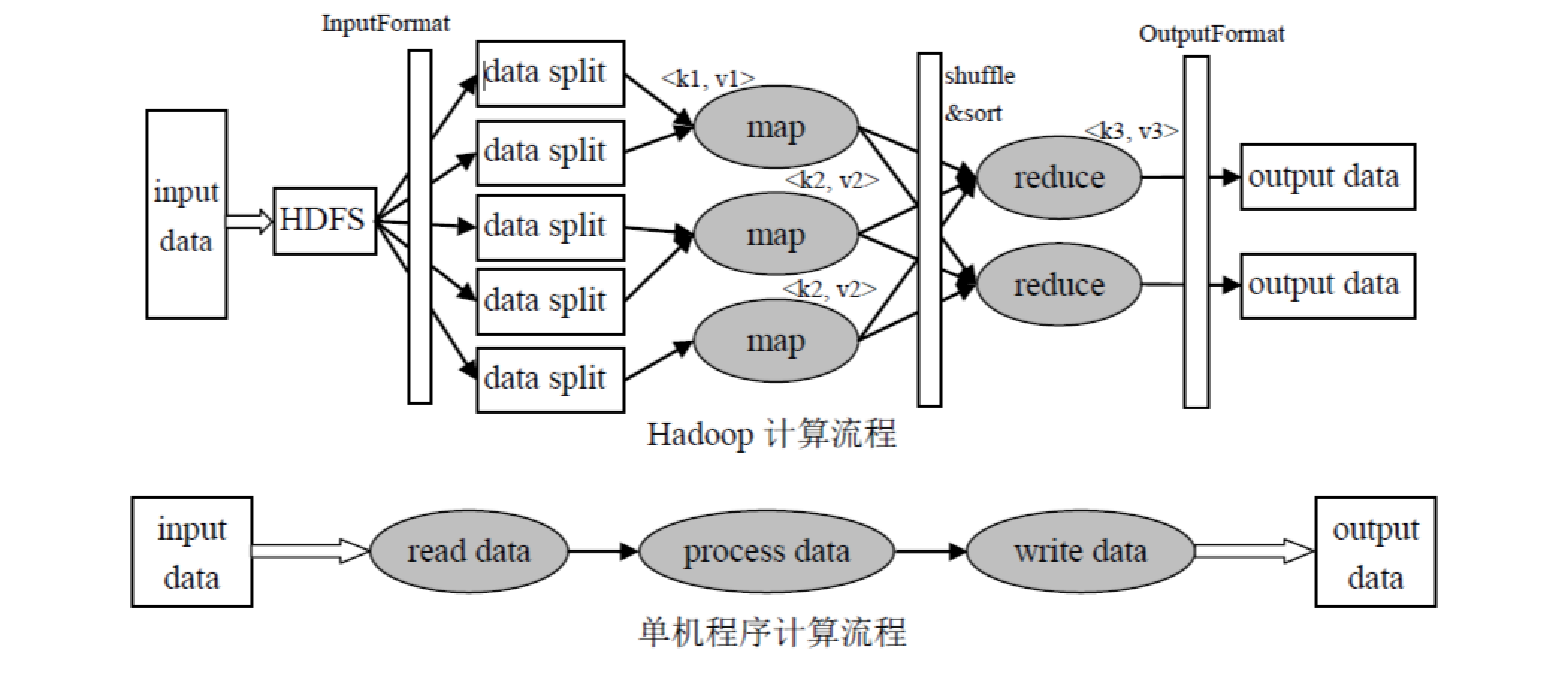
写在最前
前文提到过查询的优化问题,这里我们了解下怎么更精准地去找到到底是哪里出了问题。
结构
这里我们在hive shell里面执行任务时的日志信息,里面可以获取很多信息,这里我们先看一下Application,Task ,Job和Stage这几个概念,这里借鉴一下Spark的…1
2
3
4Application:User program built on Spark. Consists of a driver program and executors on the cluster.
Task:A unit of work that will be sent to one executor
Job:A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you'll see this term used in the driver's logs.
Stage:Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you'll see this term used in the driver's logs.
更直观地感受就是去看一下shell里输出的日志信息,里面都是有用的。这里画了一下图,助于理解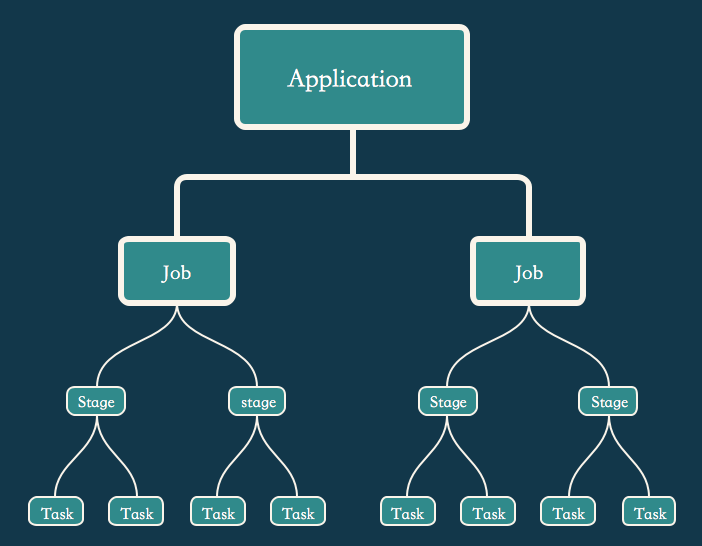
执行
- 如果发现查询过程中效率很低,这个时候先观察日志,到底是哪一步慢了,至少细化到Stage粒度
- explain yourfile.hql,查看hive的执行计划
这里就不贴实际的代码和输出的信息了,在公司环境上搞的,还是稳健一点比较好。
虽然对Spark了解不多,但感觉对其优化应该也是这么一个思路吧,后面该开始了解一下Spark了。