MapReduce的核心思想是分而治之和并行处理。
举个栗子
假设我跟一个身高一米八体重一百八的大胖哥打架,我估计我有点危险,这个时候怎么办呢?打个电话叫兄弟赛,单挑是一个打一群,群殴是一群揍一个,MapReduce大概干的也是这个事儿~
键值对
键值对的具体含义
键值数据作为MapReduce操作的基础,让MapReduce变得十分强大。因为很多数据要么本身即是键值对的形式,要么可以以键值对的形式表示,其简洁而有力,所以我们有必要清晰一下键值对的特征:
- 键必须是唯一的
- 每个值必须与键相关联,但键可能没有值
- 对键有明确的定义,比如是否区分大小写
MapReduce作为一系列键值变换
有人这么描述MapReduce:
{K1,V1} -> {K2,List<V2>} -> {K3,V3}
现在我们试图来理解一下:
- MapReduce作业中map方法的输入是一系列的键值对,我们称之为K1、V1
- map方法的输出是一系列键和与之对应的值的列表(其作为接下来reduce方法的输入),我们称之为K2、V2。注意一点是map方法输出的其实是一系列单个的键值对,需要shuffle方法组合成键与值列表
- reduce方法接受输入,输出K3、V3
MapReduce执行流程
直接看图写作文吧(图来自互联网)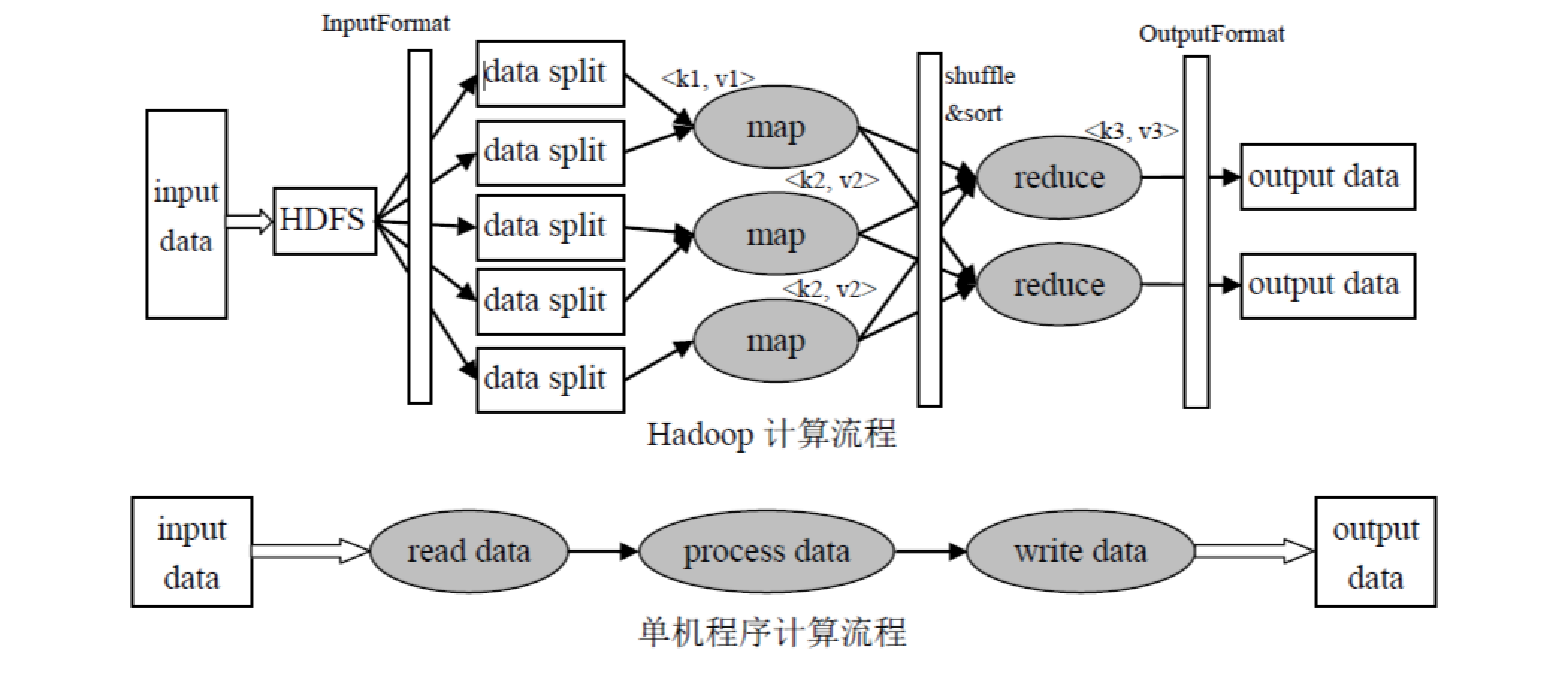
1.输入和拆分(Input&Split)
对数据内容进行分片处理,例如WordCount例子中便对每行内容拆分为单词。
2.迭代(iteration)
遍历输入数据,并将之解析成key/value对,即{K1,V1}。
3.映射(map)
将输入key/value对映射成另外一些key/value对。MapReduce开始在机器上执行map方法,map()由我们定义。
4.洗牌过程(shuffle)
依据 key 对中间数据进行分组(grouping),输出{K2,List
5.归约(reduce)
以组为单位对数据进行归约(reduce),输出{K3,V3}。
6.迭代
输出文件到HDFS。
说点屁话
讲道理到现在直接写MR程序还真没干过,都是直接用Hive搞了,节约了大量的时间,但是理解工欲善其事必先利其器,学习一下MapReduce的各种知识,感觉还是蛮有必要的。